

Ever given a through how search engines show the exact result that you are seeking for? By now, whether you have been tech-savvy or not but I am sure you must have got acquainted with the term “Web Crawling”. The question is with billions of search results out there how to make your website rank hassle freely.
Do I have your attention? Hang in there because I will start, as I always do, with the significance of crawling and a brief explanation of how it works for your eCommerce site, so we’re all on the same page.
Define Web Crawling
Web crawling is more like a web robot or spider that uses web indexing to browse the result. With the help of automated script (the one used to browse WWW and collect all the URLs), the result is combined in a single index of web result. Technically speaking, they are software that is coded to retrieve web documents through an HTTP protocol. The main objective of these crawlers is to maintain the freshness of the pages in its index.
What do they do, precisely?
Overall, they deal with a couple of major issues such as:
- What pages should be downloaded? I must say this needs to be solved of course by good crawling planning.
- To download a large number of pages per second it needs highly optimized system architecture.
In a nutshell, web crawlers gather the entire URL from the World Wide Web and then show it in the single index. As a result, users can easily find certain queries without the need of going to several URLs manually.

Significance of these Web crawlers
Many of you including me believe in the fact that web crawlers play a very crucial role in the success of an eCommerce site. Have you ever wondered how your website all of a sudden shows up when you add services and products? Isn’t it pretty obvious- web crawler?
Web crawlers incorporate a structure or pattern to show the index of URL (the one mainly being used by users). So if you are keeping your eCommerce site updated web crawler can show your search on the top of the index. Further below I would like to maintain certain benefits of the web crawlers which can push your eCommerce site to success.
- Although these tiny smart robots cannot download the entire URL and show it in the index. But they definitely show a small portion of the entire World Wide Web. Even though a small portion of the web is meaningful or not. In a layman’s language, it thoroughly checks. if you are sharing fresh and meaningful information, the web crawler will also show your URL in the index or the search engine.
- As soon as these web crawlers download a significant webpage, it needs to start revisiting the web pages for crucial changes in the information. Coded carefully to check which pages are having more information and revision to show the fresh results in the index.
- These crawlers can also turn out to be beneficial for business decisions. Imagine you are owning a shopping site that is mainly based on shopping and selling of the products and services. All you have to do is ensure that all your products compete with other competitors. But the question is how? You might need an automated procedure that can monitor the competitor’s sites and their prices.
However, the list doesn’t end here. There are a lot of things web crawlers can do for a business such as it gathers a huge amount of different data for business intelligence, or it can also search the market about the products and services you are offering. You can even keep a close eye on your rivals or other business products 24/7.
How to Optimize Crawl Budget for eCommerce sites?
As I said before, web crawlers are indeed a vital concept often got overlooked by business owners as well as SEO professionals. As a result, what we end up doing is, we tend to accept crawl budget as it is presuming we have been assigned certain quota that we have little to no impact over. But the truth is, crawl budget is something we should no matter what optimize for success of your site. Let’s delve into details
According to Google, the Crawl budget describes a number of pages on a particular site that the company’s search spider, Googlebot, can and wants to crawl. These pages are further saved, indexed, and ranked. Why is crawl budget optimization neglected?
According to Google, crawling by itself is not a ranking factor. To many of us, “not a ranking factor” is equated to “not my problem.” Which shouldn’t be the case? I strongly feel that nothing on your website is actively hurting your crawl budget.
Further below I would like to mention certain ways through which you will be able to optimize your craw budget appropriately.
#1 Cleaning
Surprisingly I stumbled upon a statement that eCommerce sites are the polygon for fighting with duplications. There are times when the same content is available on different URLs. I mean think about the sorting, flirting, internal searching options and the list goes on. All of them often result in extremely broad duplication. In short: always keep only 1 version of a URL.
So, what the issue is?
You can find a product on different URLs. For instance, the product URL containing categories like the former instead of the latter. It’s very common that products belong to two or more categories and may be available on each category path.
It may quite interest you to know that even Google admits that they crawl such pages less often than normal pages (only to check if noindex or canonical is still there), but the budget is wasted.
Clean up the XML sitemap
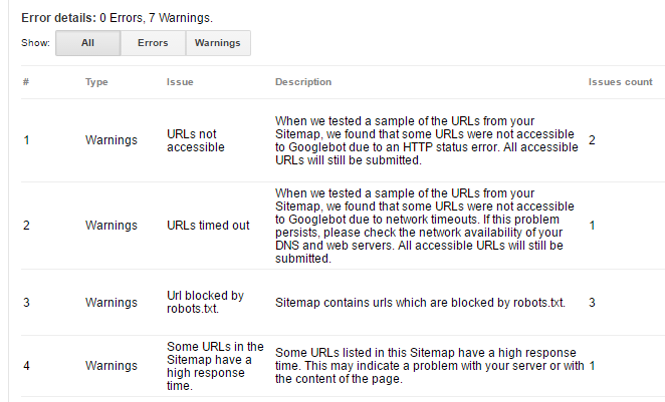
This is inevitable that XML sitemaps should contain only the most important URLs that should be visited the most frequently by GoogleBots. Google admits that the XML sitemap is used in the process of creating a list of URLs to crawl. So, it’s worth keeping the XML sitemap updated, free from errors and redirects.
 [Image Source]
[Image Source]
{kind=link}
It is very important for you to know that deep, complex website structures aren’t just unfriendly to the end-users but they have to click deeper and deeper to find the content they want. Always try to keep the most important pages as close to the homepage as possible. A good method is to organize content horizontally in the site’s structure, rather than vertically.
#2 Speed it up
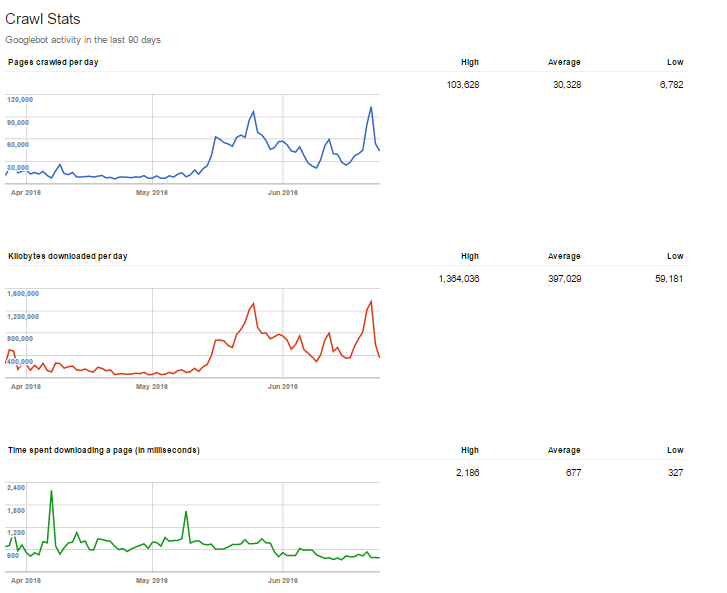
This one is quite on a roll! The faster the page loads, the better for users and you of course. And this is not because it keeps users on the website, it also ensures robots are keen to crawl your website. However, you can find a plethora of resources on how to speed the website up and you shouldn’t hesitate to read and use them. You can diagnose the problem with the performance in Deepcrawl report:
 [Image Source]
[Image Source]
{kind=link}
After detecting, it’s time to make files on the server smaller, so responses from the server to the website browser are much faster. By using GZIP Compression, you will get this results of
speeding up a website:

[Image Source]
{kind=link}
#3 Analyze server logs
Last but certainly not least, it’s time to check the effects of your crawling budget optimization. For that, you require server logs and software that will help you to analyze data. A server logs file contains data about all requests made to the server. Here you can gain any information about a host, date, requested path, the weight of the file, etc. As you may think, such files can be huge. The more frequently the website is visited, the more records there are in the file. You can use Excel, but I’d recommend dedicated software for the server log file analysis (eg. Splunk). Digging into server logs will give you information on:
- How often GoogleBots are crawling the website
- What pages are visited the most often
- How much do the crawled files weight
So that’s all for now! Go for it and make the crawl budget optimization will become a habit while doing SEO.
Author Bio – Shira Gray is working as a Business Development Executive at e-commerce Development Company – eTatvaSoft.com. She writes about emerging technologies. Being a tech geek, she keeps a close watch over the industry focusing on the latest technology news and gadgets. You can learn more about to the website.